

(ドエスタ)
ぺんぞうさん、助けてください。
たまに下記の画面のようなエラーが発生するんです。何か回避する方法ありますか?
await self._connection.wrap_api_call (
next (iter(done)).result()
といったメッセージが出てます
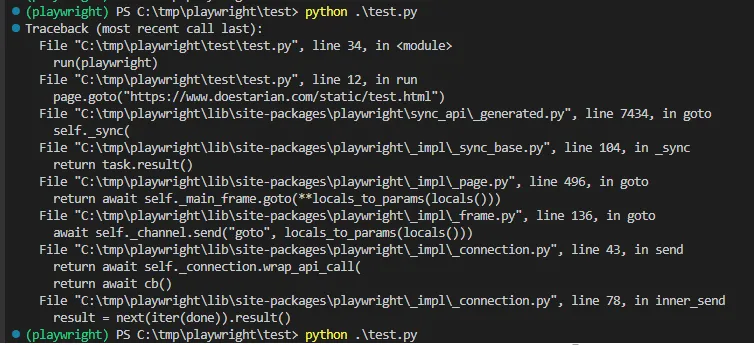
ほう、エラー箇所は12行目
page.goto("https://www.doestarian.com/static/test.html")じゃな。どうやらページの読み込みが完了できずにエラーが発生しているようじゃのう。
公式ドキュメントを見てみると読み込み完了と認識する方法が4種類あるようじゃ。
試してみてはどうじゃ。
1. エラー発生の要因(読み込み完了条件)
公式ページでは、page.gotoがエラーになる要因を下記のように紹介してます。
・SSL エラー (例: 自己署名証明書の場合)。
・ターゲット URL が無効な場合。
・ナビゲーション中にタイムアウトを超過した場合。
・リモートサーバーが応答しないか、到達不可能な場合。
・メインリソースの読み込みに失敗した。
wait_until (読み込み完了条件)
読み込み完了とみなすタイミング指定が4つあります。(Defaultは、load)
| domcontentloaded | DOMContentLoadedイベントが発生した時点で操作の終了とみなす |
| load | ロードイベントが発生した時点で操作完了とみなす |
| networkidle | 少なくとも500msの間、ネットワーク接続がない場合、操作は終了したとみなす。 |
| commit | ネットワークの応答を受信し、ドキュメントの読み込みが開始されたとき、操作が終了したとみなす |
2. 今回適用した解決策 (commit指定)
今回は簡単なHTMLなので、ドキュメントの読み込みが開始れば問題無しと判断し、
page.gotoのオプションとしてwait_until = “commit”を指定しました。
page.goto(“https://www.doestarian.com/static/test.html”,wait_until=”commit”)
参考記事を見るとdomcontentloadedでもよさそうです。
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to https://www.doestarian.com/static/test.html
page.goto("https://www.doestarian.com/static/test.html",wait_until="commit")
print(f'access OK.')
page.wait_for_timeout(3000)
# Click text=Doestarian BlogのTopページへ
page.locator("text=Doestarian BlogのTopページへ").click()
print(f'click OK.')
page.wait_for_url("https://www.doestarian.com/")
page.wait_for_timeout(3000)
# Close page
page.close()
print(f'close OK.')
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)もし、間違いやより正しい方法がありましたら是非紹介して頂けると嬉しいです。
参考
puppeteerのoptionsのメモ、とくにwaitUntilの値をよく忘れる
https://playwright.dev/python/docs/api/class-page#page-goto (公式ページ:goto)

コメント