
早速、PlaywrightでWebスクレイピング(Web Scraping)する方法を説明するぞ。Webスクレイピングとは何か知ってるかな?
(ドエスタ)
もちのろんです。
Webスクレイピング(Scraping)とは、Webサイトから必要な情報を抽出する技術のことです。
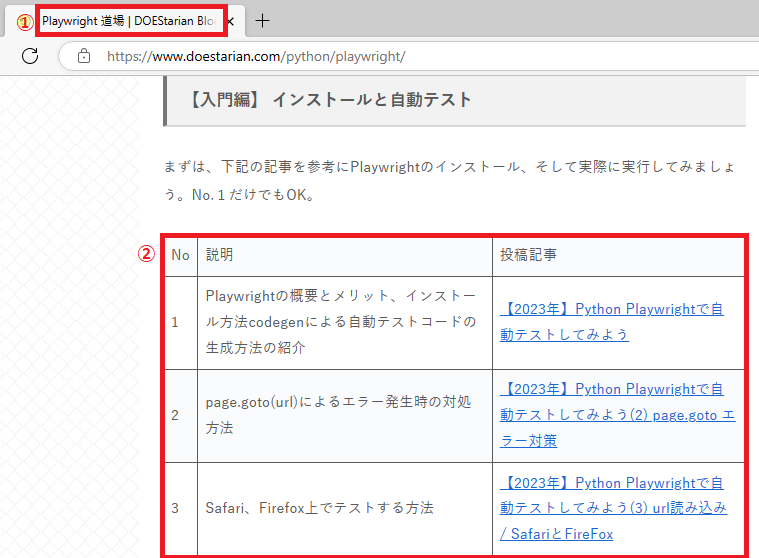
ほ、ほ、ほ、おやじギャグか、、さすがアラフィフじゃ(笑) よっぽど早くやり方を説明してほしいようじゃのう。これから、Playwright道場ページの下記の2つの情報を抽出するぞ。
【お題】
| ① タイトル名 | Playwright 道場 | DOEStarian Blog |
| ② 入門編のテーブル情報 | No. / 説明 / 投稿記事のURL |
そのまえに、Webスクレイピングのための基礎知識の習得じゃな。
HTML/CSSの構造を
page.locator()は、Page情報を抽出するPlaywrightのAPIじゃ、使い方をしっかりマスターするのじゃぞ。
1. HTMLとCSS【おさらい】
Webスクレイピングを始める前に、Webページの構造(HTMLとCSS)についてのおさらいしましょう。
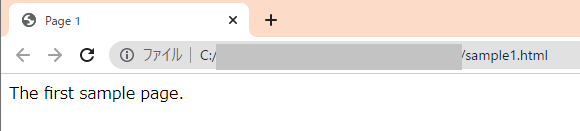
HTML(Hyper Text Markup Language)は、タグで構成されたWebページ用の言語です。これをブラウザーが解釈して表示します。例えば、テキストエディタで下記のようなHTMLファイルを作成し、ダブルクリックすると、、、
<html>
<head>
<title> Page 1</title>
</head>
<body>
The first sample page.
</body>
</html>Chromeだと、こんな感じで表示されます。
次に、CSSです。
CSS(Cascading Style Sheets)は、Webサイトにデザインを適用するための言語です。HTMLとセットで扱われ、HTMLで記述した文章構造を装飾し見栄えを良くします。
例えば、テキストエディタで下記のようなHTMLとCSSファイルを作成し、同じフォルダーにおいて、HTMLファイルをダブルクリックすると、、、
<html>
<head>
<title>Page 2</title>
<meta charset="UTF-8" />
<link rel="stylesheet" href="./style.css"/>
</head>
<body>
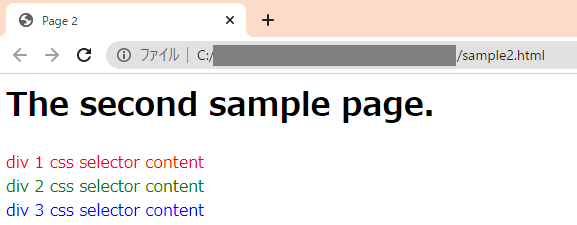
<h1> The second sample page.</h1>
<div class="div1"> div 1 css selector content </div>
<div class="div2"> div 2 css selector content </div>
<div class="div3"> div 3 css selector content </div>
</body>
</html>.div1 { color: red; }
.div2 { color: green; }
.div3 { color: blue; }Chromeだと、こんな感じで表示されます。style.cssで、div1クラスを赤、div2を緑、div3を青に装飾した結果が反映されていることが確認できると思います。
【解説】
.div1 { color: red; }
.div1 は、CSS Selectorで、装飾対象の要素を指定します。今回は、div1クラスを指定しました。
color は、プロパティで、装飾属性を指定します。今回は色属性を指定しました。
red は、値で、装飾属性の値を指定します。今回は赤を指定しました。
CSSについてはLinkで分かりやすく説明されてましたのでご参考までに、、、
2. ページ情報抽出:page.locator()
ここでは、HTMLページの情報を抽出するpage.locator()について説明します。
page.locator()は、名前の通りページ探査器で、指定ページ内の要素を返すPlaywright APIです。
# Usage
page.locator(selector)
page.locator(selector, **kwargs)
# Return
Locatorさらに、inner_text()メソッドを使ってタグ内のテキストを取得することができます。
# Usage
locator.inner_text()
locator.inner_text(**kwargs)
# Return
Str例えば、今回の例文であるsample2.htmlの下記部分を抽出するコードは、こんな感じで書けばOK。
- タイトル ”Page 2″ (<title>Page 2</title>)
- div1クラスの本文 ”div 1 css selector content ” (<div class=”div1″> div 1 css selector content </div>)
# Title抽出
title = page.locator("title").inner_text()
# div1クラスの本文抽出
div1 = page.locator("div.div1").inner_text()
# Print
print(f'title: {title}')
print(f'div1 : {div1}')実行するとこのようにPage情報を抽出することができます。

今回は、自分で作成したHTMLファイルだったので、指定セレクタ(要素)が分かっていました。しかし、実際Webスクレイピングしたいサイトは自分で作ったHTMLファイルではありませんし、ブラウザー表示した際はHTMLコードは表示されていません。
WebスクレイピングするためにはそのページのHTMLコードを確認する必要がありますので、次章ではページ内のHTMLコードから指定セレクタ(要素)の確認方法について説明します。
3. Page情報確認方法
ChromeでPageのHTMLコードを確認するための方法です。
ページ内の任意の場所で「右クリック > 検証」すると、右画面にHTMLコードが表示されます。
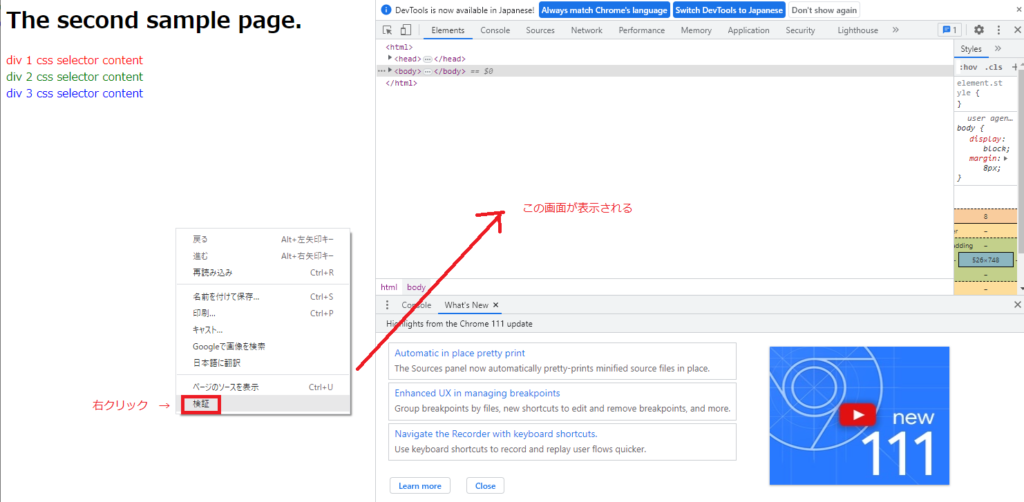
3.1 単語検索
次に、ページタイトル”Page 2”の記載場所を見つけましょう。
右側のDevTool画面の<head>タブをプルダウンして<title>を確認することもできますが、タグが分かっていない場合は確認が困難です。
こんな時は、DevTool画面上で「Ctrl+F」→「Page 2」入力 で発見できます。
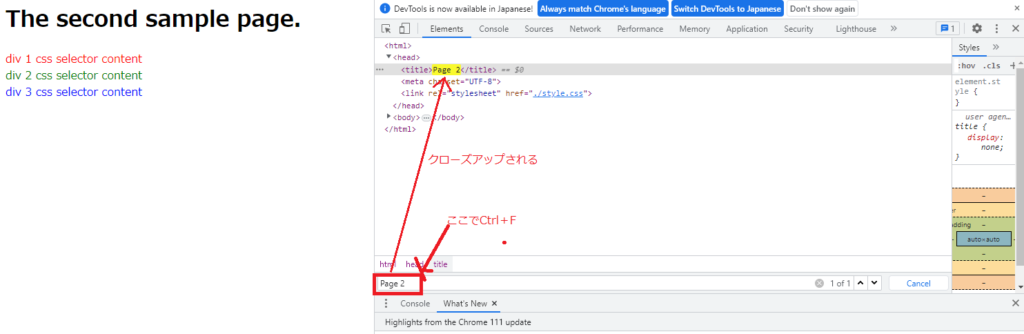
■セレクタ情報の取得
「Page 2」上で右クリック → Copy → Copy selectorでセレクタ情報を入手できます。
テキストエディタなどに貼り付けると ”head > title” が取れました。
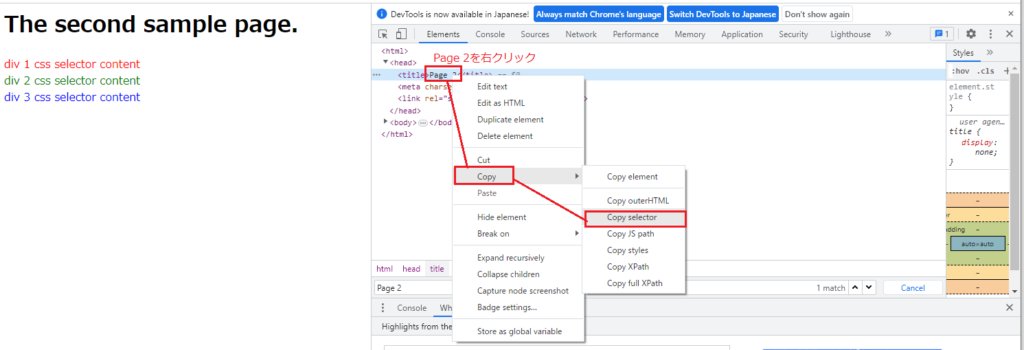
3.2 クリック検索
今度は、div1クラスの本文 ”div 1 css selector content” の記載場所を見つけましょう。
DevTool画面の左上の↖ボタンをクリック (または、Ctrl+Shift+C)
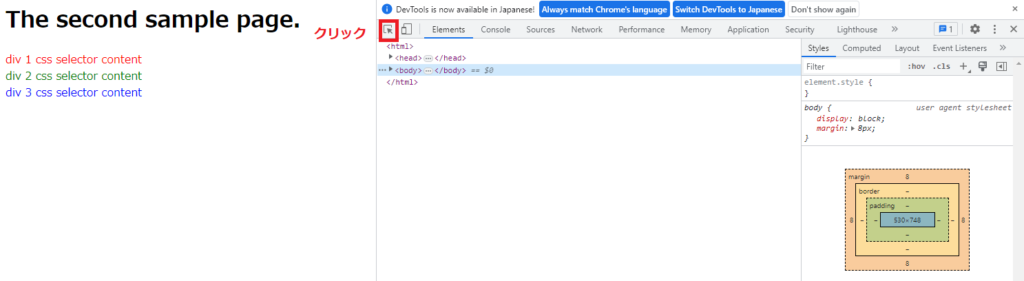
するとページ検索モード(青色)になります。
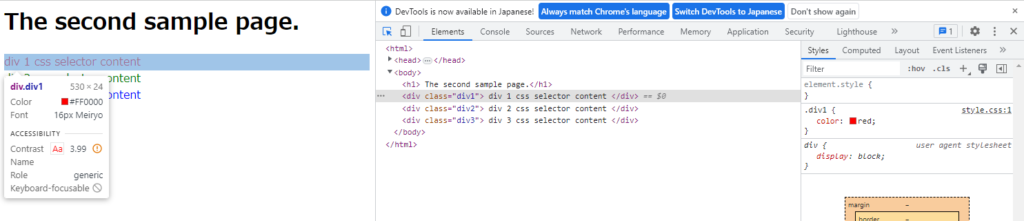
左側の実画面の”div 1 css selector content”にカーソルを当ててクリック
DevTool画面の該当箇所が表示されます。
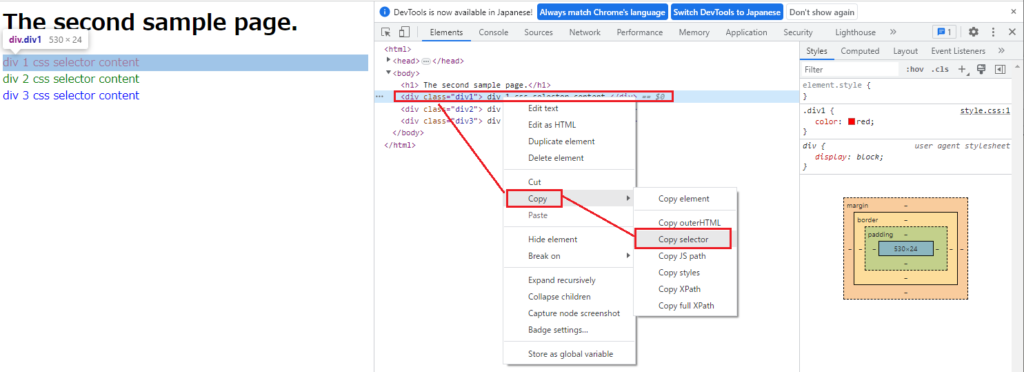
■セレクタ情報の取得
「div 1 css selector content」上で右クリック → Copy → Copy selectorでセレクタ情報を入手できます。
テキストエディタなどに貼り付けると ”body > div.div1” が取れました。
まとめ
今回は、以下のことを学びました。
- page.locator(selector).inner_text() によるPage情報の抽出方法
- Chrome DevToolによるPage内のセレクターの確認方法
今回のサンプルコードも紹介しておきます。
PC上に今回紹介したsample2.html, style.css、そして以下のsample2.pyを同じフォルダー内において動かしてみてください。
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to page
page.goto("file:///C:/xxx/sample2.html") #xxxを自分のfolder pathに変更
title = page.locator("title").inner_text()
print(f'title: {title}')
div1 = page.locator("div.div1").inner_text()
print(f'div1 : {div1}')
# Close page
page.close()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)結果出力はでましたね。
さあ、準備整いました。次回、Playwright道場ページのWebスクレイピングにトライしましょう。
<< Playwright道場
< Prev Next >
コメント