

(ドエスタ)
ペンぞうさん、前回の調査結果では、Page.gotoが処理時間が長い
(Pythonは3.8秒、WordPressは1.3秒)がわかりました。
「Pythonの調査完了を待たずにWordPressの調査を開始すれば、高速に処理できませんかね?」
下記のようなイメージで、、、
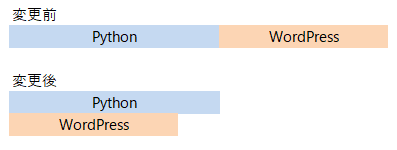
素晴らしい着眼点じゃな。提案してもらったイメージで処理するために重要な概念が2つある。
それが、非同期処理と並行処理じゃ。
非同期処理 (asynchronous processing):
待機時間や他のタスクの完了を待たずに処理を進める処理方式。
イベントのI/O待ちやネットワーク通信などの重い処理に対して待ち時間を最小限に抑えることができる。
並行処理 (concurrent processing):
複数のタスクやプロセスを同時に実行する処理方式。
同時実行することで処理時間を短縮できる(パフォーマンス向上)だけでなく、複数のプロセッサやコアに分散実行できるのでシステム全体の負荷を下げる(負荷分散)ことができる。
(ドエスタ)
なるほど~、でも、どうやってコーディングすればいいかわかりませ~ん!
1. ゴールイメージ(変更前と変更後のシーケンス図)
今回のWebスクレイピング問題のおさらいです。
これじゃぞ!
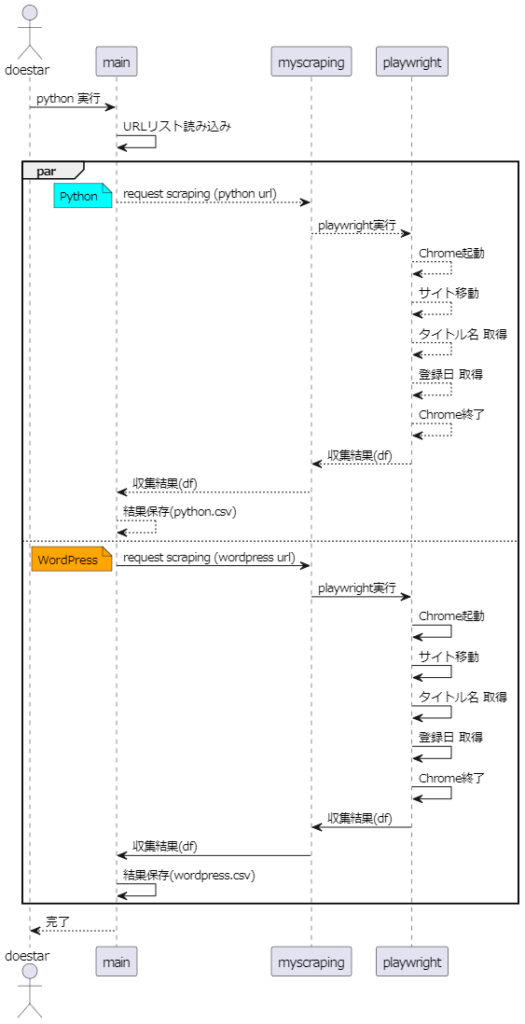
変更前と変更後でどのように処理を変えようとしているのか、シーケンス図で表現してみました。
1.1 変更前のシーケンス図
変更前の処理です。まず1つ目のCategoryであるPythonのWebスクレイピング処理が完了し、その後WordPressのWebスクレイピングを行います。各処理が実線で示されてますが、UMLシーケンス図では実線は同期処理を表しており、全処理を順番通りに逐次実行していることを示しています。

1.2 変更後のシーケンス図
次に今回目指している変更後のシーケンス図です。
Categoryであるpythonとwordpressを並行で処理します。UMLシーケンス図では、並行処理部分をparで囲んで点線で区切ります。また、点線矢印は非同期処理を表しています。
2. 高速化実験
ここでは、それぞれの実験別にソースコード(main.py , myscraping.py) と実験結果を紹介します。
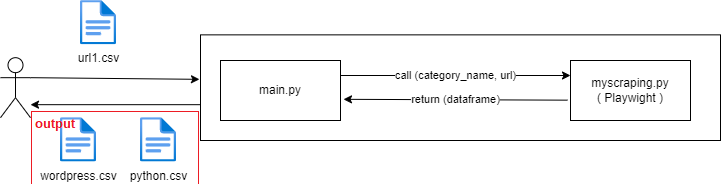
2.1 変更前
コード
import pandas as pd
import time
import myscraping
start = time.time()
# csv 読み込み
df_csv = pd.read_csv("url1.csv",index_col=0)
# scrapying report 生成
print(f'No,Result,Category,URL')
for i in range(len(df_csv)):
category = df_csv.iloc[i]['Category']
url = df_csv.iloc[i]['URL']
# スクレイピング実行
result, result_df = myscraping.scrape(url)
print(f'{i},{result}, {category}, {url}')
# 結果出力
result_csv_name = "output/"+category+".csv"
result_df.to_csv(result_csv_name, index=False)
end = time.time()
elapsed_time = end - start
print(f'経過時間:{elapsed_time:.2f} 秒')from playwright.sync_api import Playwright, sync_playwright, expect
import pandas as pd
def playwright_run(playwright: Playwright, url, df):
browser = playwright.chromium.launch(headless=True)
context = browser.new_context()
#### 1.Open url page
page = context.new_page()
page.goto(url)
#### 2.情報取得
# Title取得
titles = page.locator('h2.entry-card-title.card-title.e-card-title').all_inner_texts()
# print(titles)
# 登録日取得
entry_dates = page.locator('span.entry-date').all_inner_texts()
# print(entry_dates)
# Close page
page.close()
context.close()
browser.close()
#### 3.収集結果データ作成
new_df = pd.DataFrame({'Title': titles,'Entry_date': entry_dates})
df = pd.concat([df, new_df], ignore_index=True)
# print(df)
return "OK", df
def scrape(url):
result = "OK"
# 結果出力の空フレーム作成
cols = ['Title','Entry_date']
df = pd.DataFrame(columns=cols)
# Playwright 実行
with sync_playwright() as playwright:
result,df = playwright_run(playwright,url,df)
return result, df実験結果
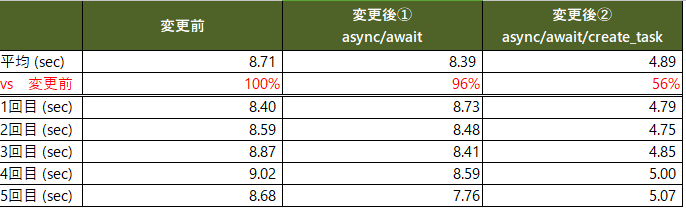
1~5回目でばらつきはあるものの4~5秒でPython終了メッセージが出て、その後3~4秒でwordpressが完了するイメージです。
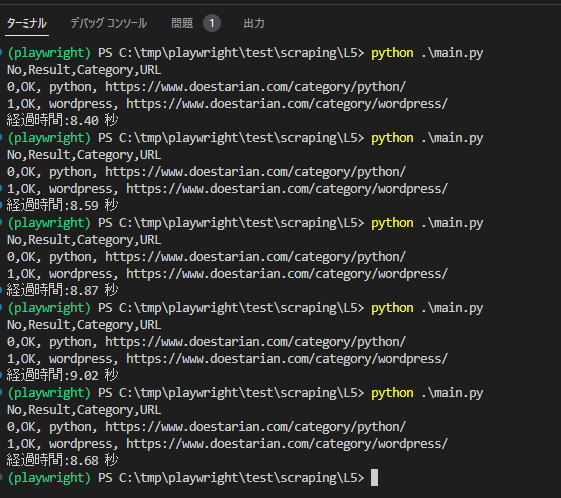
経過時間:8.40 秒
経過時間:8.59 秒
経過時間:8.87 秒
経過時間:9.02 秒
経過時間:8.68 秒
2.2 実験① (非同期)
次に、async/awaitを使って非同期にしてみました。
(参考)
https://docs.python.org/ja/3/library/asyncio-task.html (Python asyncio)
https://playwright.dev/python/docs/library (Playwright async/await)
コード
import pandas as pd
import time
import myscraping
import asyncio
start = time.time()
# csv 読み込み
df_csv = pd.read_csv("url1.csv",index_col=0)
# scrapying report 生成
print(f'No,Result,Category,URL')
for i in range(len(df_csv)):
category = df_csv.iloc[i]['Category']
url = df_csv.iloc[i]['URL']
# スクレイピング実行
result, result_df = asyncio.run(myscraping.scrape(url))
print(f'{i},{result}, {category}, {url}')
# 結果出力
result_csv_name = "output/"+category+".csv"
result_df.to_csv(result_csv_name, index=False)
end = time.time()
elapsed_time = end - start
print(f'経過時間:{elapsed_time:.2f} 秒')# 2023.5.13 (非同期対応)
import asyncio
import pandas as pd
from playwright.async_api import async_playwright
async def playwright_run(url, df):
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context()
#### 1.Open url page
page = await context.new_page()
await page.goto(url)
#### 2.情報取得
# Title取得
titles = await page.locator('h2.entry-card-title.card-title.e-card-title').all_inner_texts()
# print(titles)
# 登録日取得
entry_dates = await page.locator('span.entry-date').all_inner_texts()
# print(entry_dates)
# Close page
await page.close()
await context.close()
await browser.close()
#### 3.収集結果データ作成
new_df = pd.DataFrame({'Title': titles,'Entry_date': entry_dates})
df = pd.concat([df, new_df], ignore_index=True)
# print(df)
return "OK", df
async def scrape(url):
result = "OK"
# 結果出力の空フレーム作成
cols = ['Title', 'Entry_date']
df = pd.DataFrame(columns=cols)
# Playwright 実行
result, df = await playwright_run(url, df)
return result, df
# main
if __name__ == "__main__":
url = "https://www.doestarian.com/category/python/"
result, ret_df = asyncio.run(scrape(url))
print(f'result:{result}')
print(f'result_df:\n{ret_df}')実験結果
pythonとwordpressがほぼ同時に表示されるようになりましたが、思ったより高速化されてないですね。単純に非同期にしただけでは効果は薄いようです。
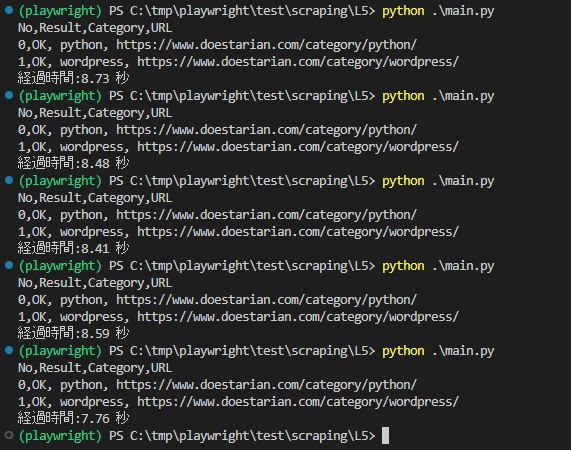
経過時間:8.73 秒
経過時間:8.48 秒
経過時間:8.41 秒
経過時間:8.59 秒
経過時間:7.76 秒
2.3 実験② (非同期+並行)
python と wordpressの並行処理が行われてないが、
asyncio.create_task() でタスクを生成し、asyncio.gather()でタスクの並行処理ができるぞ。
どのくらい早くなるかためしてみてはいかがかな?
(参考)
https://docs.python.org/ja/3/library/asyncio-task.html (asyncio.create_task / async.gather)
最近のPythonでのコンカレント(並列)の非同期処理 async/await ・asyncioについて(ver 3.8で確認)
コード
import pandas as pd
import time
import myscraping
import asyncio
async def scrape_task(i,category, url):
# スクレイピング実行
result, result_df = await myscraping.scrape(url)
# 結果出力
print(f'{i},{result}, {category}, {url}')
result_csv_name = f"output/{category}.csv"
result_df.to_csv(result_csv_name, index=False)
async def main():
# csv 読み込み
df_csv = pd.read_csv("url1.csv", index_col=0)
# スクレイピング
tasks = []
for i in range(len(df_csv)):
category = df_csv.iloc[i]["Category"]
url = df_csv.iloc[i]["URL"]
tasks.append(asyncio.create_task(scrape_task(i,category, url)))
# mainを並列
# https://qiita.com/smatsumt/items/d8f290e40077a14210f2
await asyncio.gather(*tasks)
if __name__ == "__main__":
start = time.time()
asyncio.run(main())
end = time.time()
elapsed_time = end - start
print(f'経過時間:{elapsed_time:.2f} 秒')
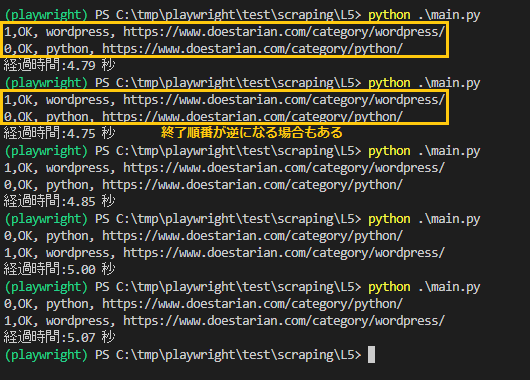
実験結果
明らかに高速化されたことを実感しました。またwordpressがpythonより処理完了が早い場合もありました。
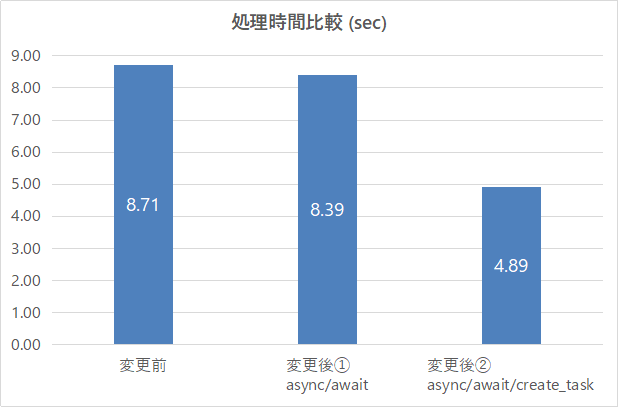
2.4 実験結果まとめ
結果をまとめです。非同期+並行処理により変更前より44%も高速化できました。
実験PCのスペック
CPU :Intel(R) Core(TM) i5-4200M CPU @ 2.50GHz
Memory:8.00 GB
OS : Windows 10 Pro (64ビット)
さいごに
今まで、「非同期+並行処理すれば高速化できるんだろうなあ、でもそこまで処理時間求めてないし、、コードも見づらくなるの嫌だな」といった理由で取り組んできませんでした。
でも、この実験を通して、今後は積極的に非同期、並行処理処理を適用していこうとおもいます。
コメント