

(ドエスタ)
ぺんぞうさん、サイトからデータを抽出するWebスクレイピングって技術、
私もやってみたいんだけど、Pythonでできるかな?
いろいろ調べると、SeleniumとかBeautilsoup とかPythonのフレームワークで作れることが分かったよ。でも、実際どのフレームワークを使えばいいかわからないんだよね~
自分でやりたいことを調べる、良い姿勢じゃ。
SeleniumはWebスクレイピングとして、最も知名度の高いフレームワークじゃな。
フレームワークの進化は恐ろしく早いし、
それぞれのフレームワークでメリット・デメリットがあるので断言はできないが、
2023年2月25日時点でのわしの1番のおすすめは、Playwright じゃ!
Scrapyも良いのう。どちらもよくできたフレームワークじゃ。
これから、Playwrightについておすすめする理由も含めて解説するぞ。
もし、さきに試したかったら解説はよみ飛ばしてくれたまえ。
理由は3つじゃ。
- 注目度が高い
- メンテナンス面で安心
- 実装しやすい
次からPlaywrightについて簡単に解説するぞ。
1. Playwrightとは
Playwrightは、Webテストと自動化のためのフレームワークです。
Pythonだけでなく.NET, TypeScript,Javascript, Javaなどの複数言語のAPIをサポートしています。
また、Chromium、Firefox、WebKit(Safari)の複数ブラウザーや、
Windows, Linux, macOSなどのOS上でも、API自動テストや、Webスクレイピングを行うことができます。
公式サイトは、こちら
Playwright をお勧めする3つの理由 (2024年1月27日現在)
① 注目度が高い
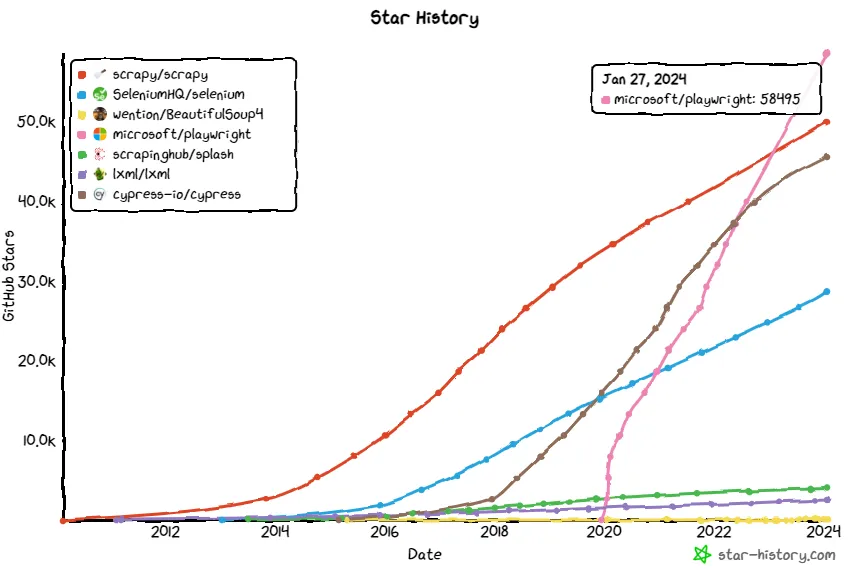
GitHubのStar履歴を見てみるとPlaywrightが急上昇、そしてScrapyを逆転し、現在注目度No.1です。
② メンテナンス面が安心
Microsoft社製のフレームワークなので安心ですね。不具合改修などのメンテナンスをしっかりやってくれるはず。個人で作成したフレームワークなど、突然開発がストップするケースなどありますから。
https://github.com/microsoft/playwright
③ 実装が楽(特に自動コード生成)
ブラウザー操作を一からコード化するの大変ですよね~。
playwrightは codegen という、ユーザーのブラウザー操作を録画してコード生成するすぐれたコマンドがあります。
おそらくこのコマンドがPlaywrightの注目が高い要因になっていると予想しています。
(公式サイトのcodegenページは、こちら)
2. Playwrightで自動テスト
ここではPlaywrightにて、下記を実行するテストプログラム(test.py) を生成してみようとおもいます。
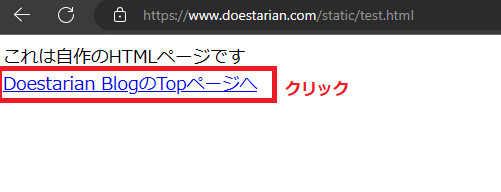
1.テストページにアクセスする (https://www.doestarian.com/static/test.html )
2.「Doestarian BlogのTopページへ」をクリックする
0. 準備:Playwrightのインストール
下記の手順でplaywrightをインストールする (参考:公式ページ)
pip install --upgrade pip
pip install playwright
playwright install1. コード生成 (test.py作成)
下記の手順で自動テストプログラムを実行しましょう。
■フォーマット
playwright codegen アクセスしたいサイトURL -o ファイル名
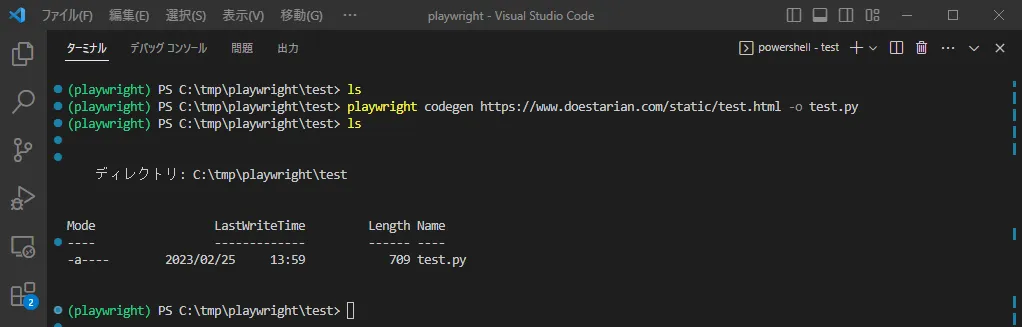
■今回のサンプル
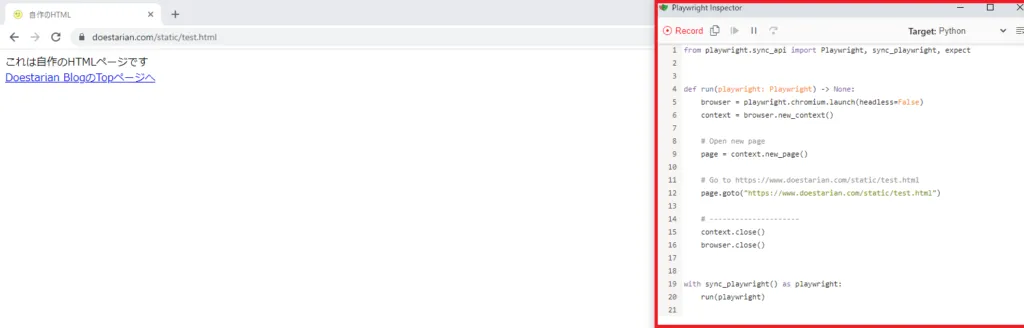
playwright codegen https://www.doestarian.com/static/test.html -o test.py実行して、

しばらくすると、アクセスしたいサイトURLのページとPlaywrightのレコーディング画面が表示されます。
そしてブラウザ操作を実行し終わったらブラウザを×ボタンで閉じます。
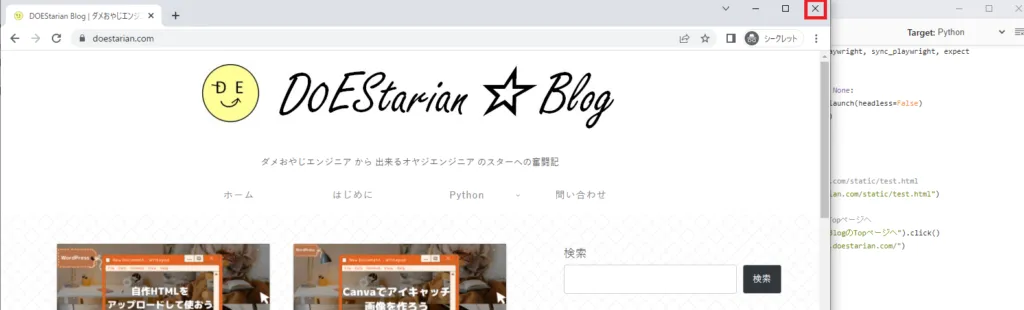
するとレコーディング画面も自動的に終了し、コードが生成されました。
2. コードの実行確認
実際に作成されたコードがこちらになります。
動作が分かるようにPrint文と待ち時間(3秒)page.wait_for_timeout(3000) を追加しました。
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to https://www.doestarian.com/static/test.html
page.goto("https://www.doestarian.com/static/test.html")
print(f'access OK.')
page.wait_for_timeout(3000)
# Click text=Doestarian BlogのTopページへ
page.locator("text=Doestarian BlogのTopページへ").click()
print(f'click OK.')
page.wait_for_url("https://www.doestarian.com/")
page.wait_for_timeout(3000)
# Close page
page.close()
print(f'close OK.')
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)実際に動かしてみましょう。

できました!
今後は、PlaywrightでWebスクレイピングする方法などさらに紹介していこうとおもいます。
【うまく読み込めない場合】
たまにページがうまく読み込めない場合があるようです。
もしpage.gotoでエラーが発生した場合は、下記リンクで回避策を紹介していますのでご参照ください。
【2023年】Python Playwrightで自動テストしてみよう(2) page.goto エラー対策


コメント