

(ドエスタ)
ペンぞうさん、「処理時間が長い気がします。もっと高速に処理できませんか?」
ブラウザ操作だからそこまでスピードは期待できないんじゃが、せっかくなので前回のどこが遅いか「Trace Viewer」を使って調査してみようかのう~
1. Trace Viewerとは
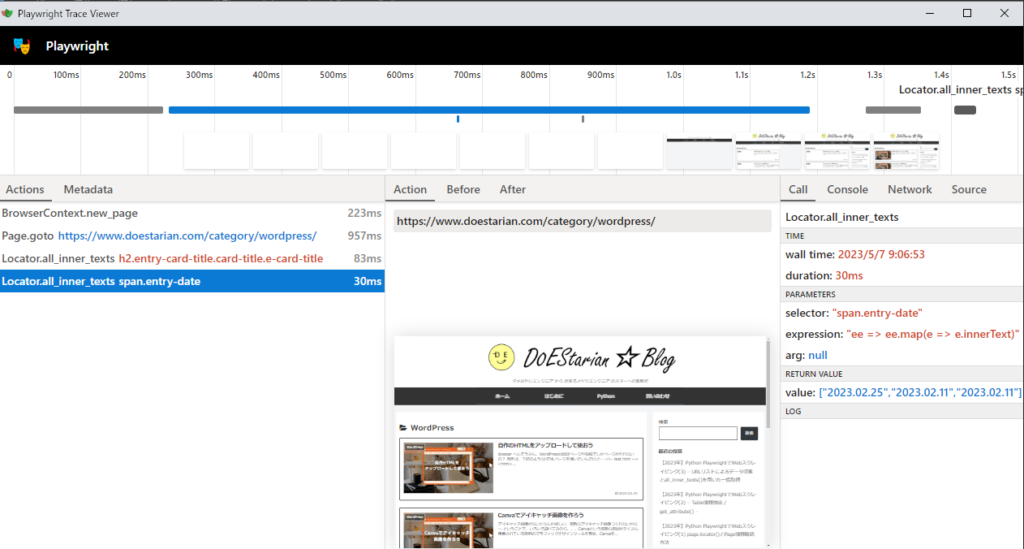
Trace Viewerとは、スクリプト実行後に記録された Playwright のトレースを探索するのに役立つ GUI ツールです。下記は、TraceViewerのサンプル画面です。
2.Trace Viewer の設定と実行
TraceViewerで出力する方法は、簡単です。
1.TraceViewer出力コードを追記
2.スクレイピング実行後、show-traceコマンドでTraceViewerを開く
1. TraceViewer出力コードを追記
設定箇所は2ヵ所です。
1つは、ブラウザ操作開始直後に、context.tracing.start()を設定 : 9~10行目
# Start tracing before creating / navigating a page.
context.tracing.start(screenshots=True, snapshots=True, sources=True)もう1つは、ブラウザ操作終了直前に、context.tracing.stop()を設定:28~29行目
# Stop tracing and export it into a zip archive.
context.tracing.stop(path = "trace.zip") from playwright.sync_api import Playwright, sync_playwright, expect
import pandas as pd
def playwright_run(playwright: Playwright, url, df):
browser = playwright.chromium.launch(headless=True)
context = browser.new_context()
# Start tracing before creating / navigating a page.
context.tracing.start(screenshots=True, snapshots=True, sources=True)
#### 1.Open url page
page = context.new_page()
page.goto(url)
#### 2.情報取得
# Title取得
titles = page.locator('h2.entry-card-title.card-title.e-card-title').all_inner_texts()
# print(titles)
# 登録日取得
entry_dates = page.locator('span.entry-date').all_inner_texts()
# print(entry_dates)
# Close page
page.close()
# Stop tracing and export it into a zip archive.
context.tracing.stop(path = "trace.zip")
context.close()
browser.close()
#### 3.収集結果データ作成
new_df = pd.DataFrame({'Title': titles,'Entry_date': entry_dates})
df = pd.concat([df, new_df], ignore_index=True)
# print(df)
return "OK", df
def scrape(url):
result = "OK"
# 結果出力の空フレーム作成
cols = ['Title','Entry_date']
df = pd.DataFrame(columns=cols)
# Playwright 実行
with sync_playwright() as playwright:
result,df = playwright_run(playwright,url,df)
return result, df2. スクレイピング実行後、show-traceコマンドでTraceViewerを開く
python main.py
playwright show-trace .\trace.zip
これらを実行すると、TraceViewerが開きます。
3.処理時間分析
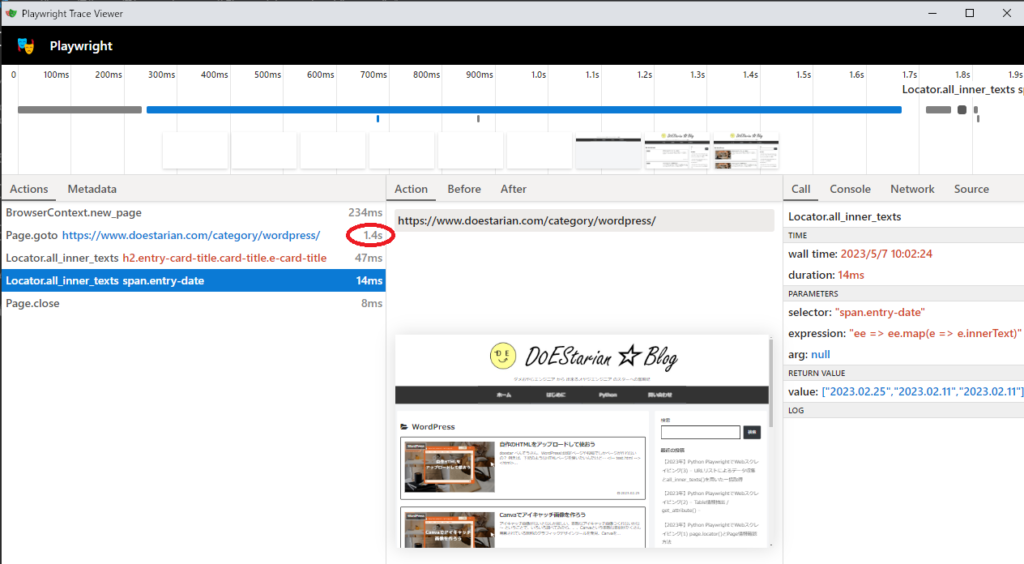
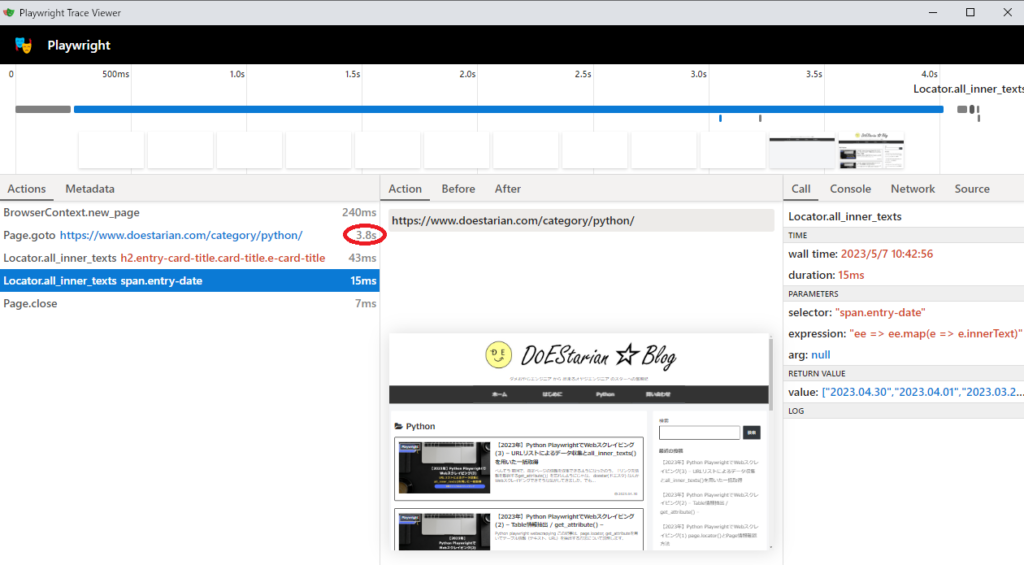
カテゴリは2つあり、Python→WordPressの順番でplaywright_run() 関数が2回呼ばれますので関数内で生成されたtrace.zipは、WordPress時の実行結果が表示されています。
上記の赤丸をみると、Page.gotoで指定ページを開くのに1.4秒もかかっていることが分かりますね。
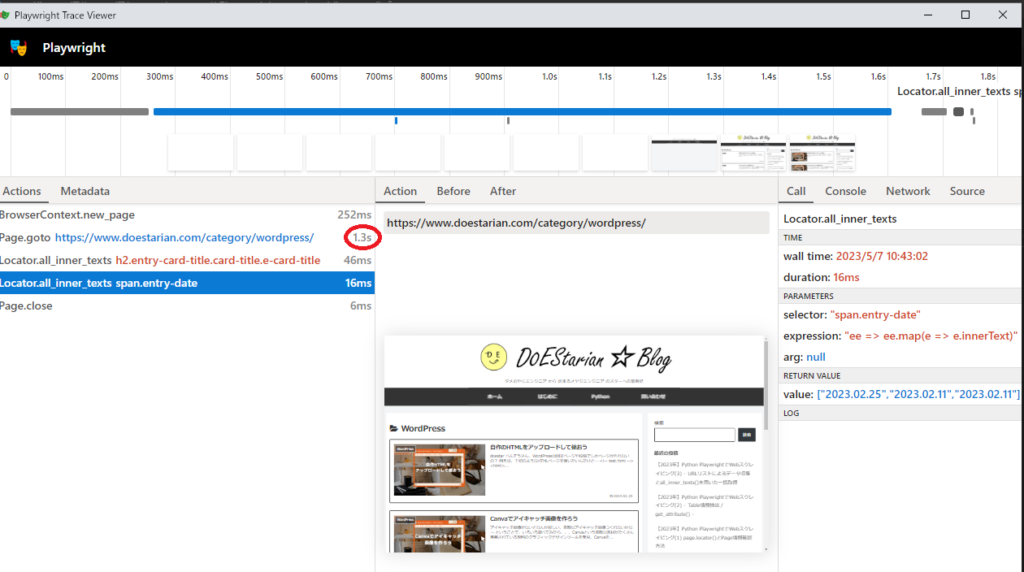
最初のカテゴリPythonも出力結果が確認できるように少しプログラムを細工して調査してみました。
(といっても、trace0.zip, trace1.zipと順番でとれるようにしただけですが、、、)
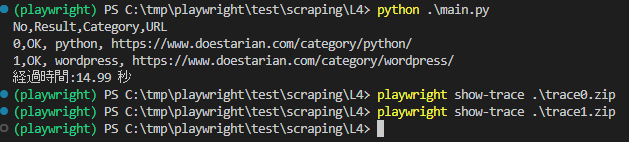
調べてみると、Pythonは3.8秒、wordpressは1.3秒とPage.gotoが処理時間で多くの時間を使っているのが確認できました。
#====================================================
# main.py
# (url1.csvのデータ収集)
#
# V1.0 2023.4.23 : 初版
# V1.1 2023.5.7 : myscraping.scrape引数追加(url)->(i,url)
#====================================================
import pandas as pd
import time
import myscraping
start = time.time()
# csv 読み込み
df_csv = pd.read_csv("url1.csv",index_col=0)
# scrapying report 生成
print(f'No,Result,Category,URL')
for i in range(len(df_csv)):
category = df_csv.iloc[i]['Category']
url = df_csv.iloc[i]['URL']
# スクレイピング実行
result, result_df = myscraping.scrape(i,url)
print(f'{i},{result}, {category}, {url}')
# 結果出力
result_csv_name = "output/"+category+".csv"
result_df.to_csv(result_csv_name, index=False)
end = time.time()
elapsed_time = end - start
print(f'経過時間:{elapsed_time:.2f} 秒')from playwright.sync_api import Playwright, sync_playwright, expect
import pandas as pd
def playwright_run(playwright: Playwright, i,url, df):
browser = playwright.chromium.launch(headless=True)
context = browser.new_context()
# Start tracing before creating / navigating a page.
context.tracing.start(screenshots=True, snapshots=True, sources=True)
#### 1.Open url page
page = context.new_page()
page.goto(url)
#### 2.情報取得
# Title取得
titles = page.locator('h2.entry-card-title.card-title.e-card-title').all_inner_texts()
# print(titles)
# 登録日取得
entry_dates = page.locator('span.entry-date').all_inner_texts()
# print(entry_dates)
# Close page
page.close()
# Stop tracing and export it into a zip archive.
trace_filename = f'trace{i}.zip'
context.tracing.stop(path = trace_filename)
# context.tracing.stop(path = "trace.zip")
context.close()
browser.close()
#### 3.収集結果データ作成
new_df = pd.DataFrame({'Title': titles,'Entry_date': entry_dates})
df = pd.concat([df, new_df], ignore_index=True)
# print(df)
return "OK", df
def scrape(i,url):
result = "OK"
# 結果出力の空フレーム作成
cols = ['Title','Entry_date']
df = pd.DataFrame(columns=cols)
# Playwright 実行
with sync_playwright() as playwright:
result,df = playwright_run(playwright,i,url,df)
return result, df
# main
if __name__ == "__main__":
url = "https://www.doestarian.com/category/python/"
result, ret_df = scrape(url)
print(f'result:{result}')
print(f'result_df:\n{ret_df}')さいごに
いかがでしたでしょうか?今回はTraceViewerにて、処理時間分析する方法を紹介しました。
今回の出力結果を受けてPython、WordPressの2つのカテゴリを順番に開くのではなく、非同期で別々に処理したら高速化できるのではないか?と考えました。
次回は、非同期でどれくらい高速になるか試してみようと思います。
コメント