

(ドエスタ)
ペンぞうさん、Webスクレイピング(3)では、スクレイピング結果をCSV保存しました。
でもね、サイト内ののDownloadボタンクリック時して欲しいファイルを一括保存したい
ときがあります。ダウンロード先のフォルダーも指定したいんです。できます?
ほう、ファイルダウンロードじゃな。Playwrightにも、Downloadメソッドが用意されとるぞ。今回、わしが特別にダウンロードテスト用のサンプルサイトを作ったのでそこにアクセスして試してもらおうかの~、では早速始めるぞ!
問題: アイキャッチ画像をファイル保存
下記 Download Testページ内にあるアイキャッチ画像横のダウンロード(赤枠)をクリックし、
指定フォルダーにアイキャッチ画像ファイルを保存してください。
(Download Test)
https://www.doestarian.com/python/playwright/download-test/
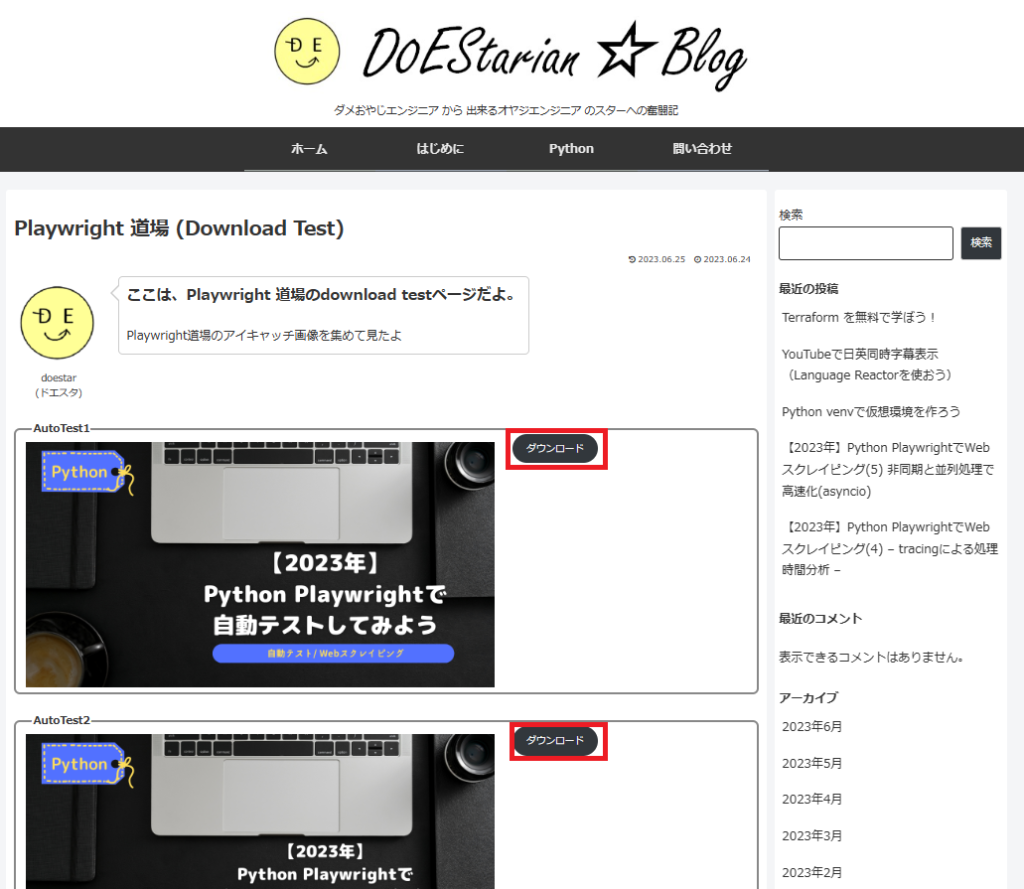
出力結果例です。
私は、”dl”という名のフォルダーを作ってそこに保存しました。
1.解説
ここでは、私が問題を解くまでの過程をご紹介します。
今すぐ解答を見たい方は、2.解答サンプルへ急ぎましょ!
1-1. Codegenでサンプルコード生成(ダウンロードボタンをクリック)
ダウンロードをクリックしてファイル保存するコードはどう書けばよいのでしょうか?
以前、自動テスト(1)でご紹介した 自動生成機能 (Codegen)を使って、実際にダウンロードボタンをクリックしてサンプルコードを作ってみましょう。
playwright codegen https://www.doestarian.com/python/playwright/download-test/ -o test.py
こちらが test.pyで得られたDownloadボタンクリック近辺のコード抜粋です。page.expect_download()というメソッドを使っているようです。
# Go to https://www.doestarian.com/python/playwright/download-test/
page.goto("https://www.doestarian.com/python/playwright/download-test/")
# Click text=AutoTest1 ダウンロード >> a
with page.expect_download() as download_info:
page.locator("text=AutoTest1 ダウンロード >> a").click()
download = download_info.value1-2. ダウンロード:page.expect_download()
では、さっそくメソッドを調べてみましょう。
Playwrightの公式ページ、https://playwright.dev/python/docs/downloads を見ると、、
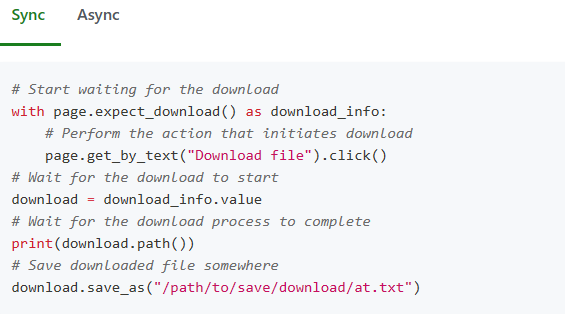
download.save_as(”ファイル名”)で保存先を指定できるようです。
また、get_by_text(“ダウンロードボタン名”)でクリックするみたいですが、今回のボタンはすべて”ダウンロード”なので、アイキャッチ画像保存ファイル名が、全て”ダウンロード.png” になってしまいます、ファイル名からアイキャッチ画像を判別できないのでちょっと不便ですね。
Codegenで生成したコードは、
page.locator(“text=AutoTest1 ダウンロード >> a“).click()
でしたので、page.locatorに設定するtext名を利用してAutoTest1.pngのように保存したいです。
次節で、AutoTest1 ダウンロード >> aの部分のCSSについて調査していきましょう。
1-3. DownloadボタンのCSS Selector調査
Codegenで生成したコードは、
page.locator(“text=AutoTest1 ダウンロード >> a”).click()
でしたね。
では、ダウンロードボタンのCSSをブラウザのデベロッパーツール(Ctrl + Shift + i)を開いて確認してみましょう。
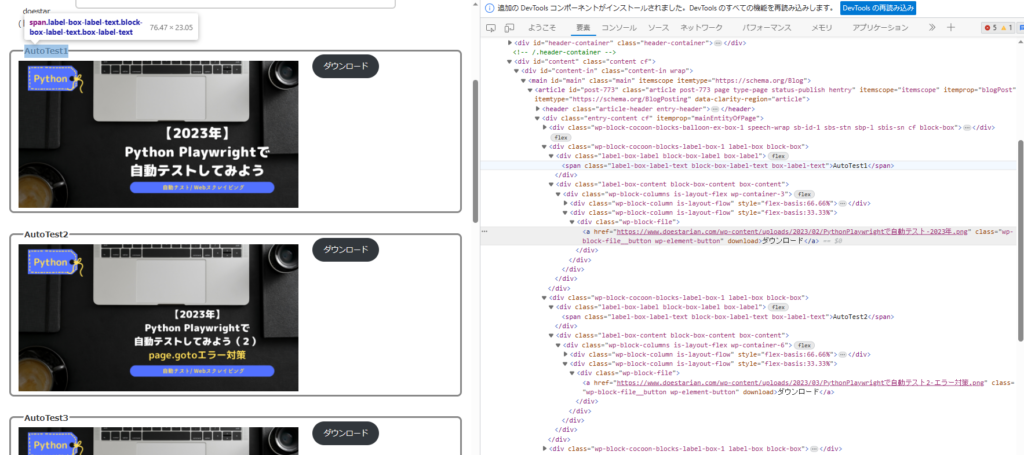
ダウンロードボタンのCSSSelectorを1番目、2番目、、最後を確認すると
## AutoTest1のダウンロードボタン
#post-773 > div > div:nth-child(2) > div.label-box-content.block-box-content.box-content > div > div:nth-child(2) > div > a
## AutoTest2のダウンロードボタン
#post-773 > div > div:nth-child(3) > div.label-box-content.block-box-content.box-content > div > div:nth-child(2) > div > a
(省略)
## WebScraping5のダウンロードボタン
#post-773 > div > div:nth-child(9) > div.label-box-content.block-box-content.box-content > div > div:nth-child(2) > div > a
AutoTest1のCSSSelectorを1番目、2番目から調査すると、、
## AutoTest1 テキスト
#post-773 > div > div:nth-child(2) > div.label-box-label.block-box-label.box-label > span
## AutoTest2 テキスト
#post-773 > div > div:nth-child(3) > div.label-box-label.block-box-label.box-label > spanpost-773 > div > div:nth-child(X) の部分は共通でしたので
「div.label-box-label.block-box-label.box-label > span」の取得値 ダウンロード >> aを利用すれば、下記のようなファイル名でダウンロードできそうです。
- AutoTest1.png
- AutoTest2.png
- (省略)
- Webscraping5.png
こんな感じできました! 次章で解答サンプルを紹介します。
2. 解答サンプル(コードと trace調査)
今回も同期・非同期でコードを書いてみましたのでご参考までに、、、
やっぱり最適化した非同期コードは高速です。
今回のサンプルコードには、Webスクレイピング(4)で紹介した処理時間解析用のtraceコマンド(context.tracing.start / context.tracing.stop)を含んだmain_trace.pyというファイルで紹介しています。その後、trace解析結果を記載しています。
実際の計測では、traceコマンドを除いたmain.pyというファイルで計測してます。

2.1 解答サンプル(sync)
コード
シンプルなsync型のコードです。
from playwright.sync_api import Playwright, sync_playwright, expect
import time
#----------------------------------------------------
# playwright run
#----------------------------------------------------
def playwright_run(playwright: Playwright, url):
browser = playwright.chromium.launch(headless=True)
context = browser.new_context()
# Start tracing before creating / navigating a page.
context.tracing.start(screenshots=True, snapshots=True, sources=True)
#### 1.Open url page
page = context.new_page()
page.goto(url)
#### 2. Get title of download button.
# ダウンロードボタンのタイトル名をリストで取得
titles = page.locator('div.label-box-label.block-box-label.box-label > span').all_inner_texts()
# print(titles)
#### 3. Download data(Click download button)
for title in titles:
with page.expect_download() as download_info:
target=f'text={title} ダウンロード >> a'
page.locator(target).click()
download = download_info.value
download.save_as(f'dl/{title}.png')
# Stop tracing and export it into a zip archive.
context.tracing.stop(path = "trace_sync.zip")
#### 4. Close page
page.close()
context.close()
browser.close()
return "OK"
#----------------------------------------------------
# main
#----------------------------------------------------
if __name__ == "__main__":
print(f'--> Download Start.')
start = time.time()
# Download Test Page
url = "https://www.doestarian.com/python/playwright/download-test/"
# Playwright 実行
with sync_playwright() as playwright:
result = playwright_run(playwright,url)
print(f'result:{result}')
end = time.time()
elapsed_time = end - start
print(f'経過時間:{elapsed_time:.2f} 秒')trace解析
traceコマンドを実行して処理時間を解析しましょう。
playwright show-trace .\trace_sync.zip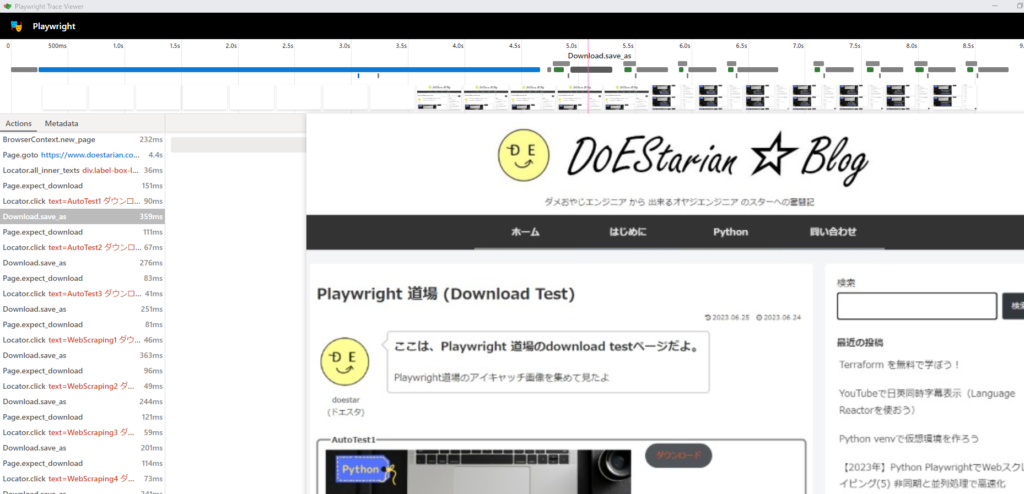
Download.save.asで約200ms~400msと時間がかかっていることがわかります。
ほかにもPage.expect_downloadでDownloadボタンをクリックまでも100ms超かかっていますね。
計測結果
main.pyの計測結果です。
経過時間:8.95 秒
経過時間:9.20 秒
経過時間:9.46 秒
経過時間:9.23 秒
経過時間:8.99 秒
2.2 解答サンプル(async)
次に、asyncコードです。 単純にsync部分をasyncに置き換えました。
コード
import asyncio
from playwright.async_api import async_playwright
import time
#----------------------------------------------------
# playwright run
#----------------------------------------------------
async def main(url):
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context()
# Start tracing before creating / navigating a page.
await context.tracing.start(screenshots=True, snapshots=True, sources=True)
#### 1.Open url page
page = await context.new_page()
await page.goto(url)
#### 2. Get title of download button.
# ダウンロードボタンのタイトル名をリストで取得
titles = await page.locator('div.label-box-label.block-box-label.box-label > span').all_inner_texts()
# print(titles)
#### 3. Download data(Click download button) [async]
for title in titles:
async with page.expect_download() as download_info:
target=f'text={title} ダウンロード >> a'
await page.locator(target).click()
download = await download_info.value
await download.save_as(f'dl/{title}.png')
# Stop tracing and export it into a zip archive.
await context.tracing.stop(path = "trace_async.zip")
#### 4. Close page
await page.close()
await context.close()
await browser.close()
return "OK"
#----------------------------------------------------
# main
#----------------------------------------------------
if __name__ == "__main__":
print(f'--> Download Start[async].')
start = time.time()
# Download Test Page
url = "https://www.doestarian.com/python/playwright/download-test/"
# Playwright 実行
result = asyncio.run(main(url))
print(f'result:{result}')
end = time.time()
elapsed_time = end - start
print(f'経過時間:{elapsed_time:.2f} 秒')
trace解析
今回も、traceコマンドで実行しましょう。
playwright show-trace .\trace_async.zip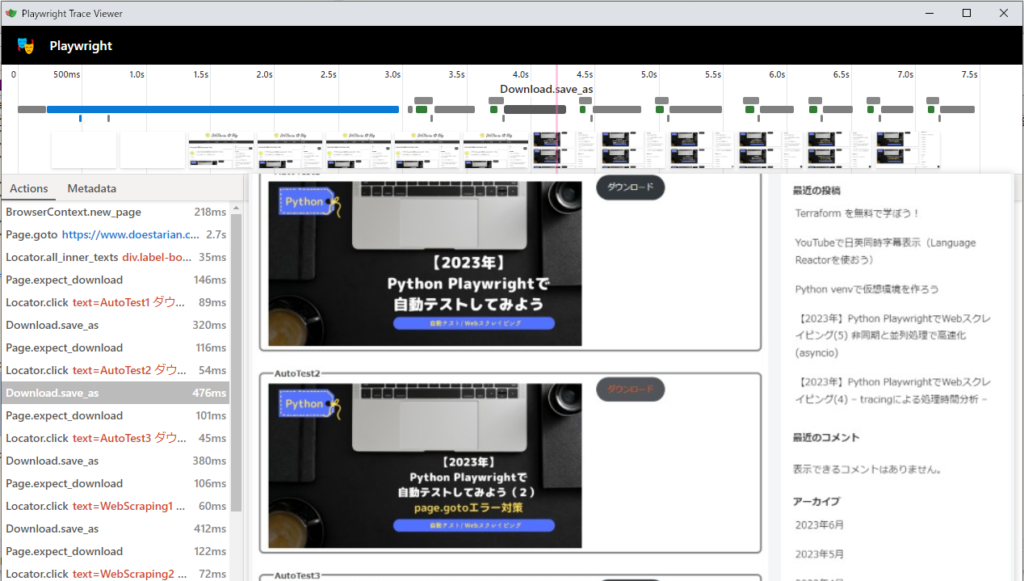
syncで実行した時より、Download.save_as から次の page.expect_download の隙間が少なくなったけどまだまだですね。ダウンロード部分を並行で動かしたいです。
計測結果
main.pyの計測結果です。syncよりは高速ですが、体感はあまり変わらないですね。
経過時間:8.65 秒
経過時間:8.30 秒
経過時間:8.34 秒
経過時間:8.57 秒
経過時間:8.65 秒
2.3 解答サンプル(async_task)
asyncの下記コードの部分を切り出してマルチタスクで動作させるように変更しました。
#### 3. Download data(Click download button) [async]
for title in titles:
async with page.expect_download() as download_info:
target=f'text={title} ダウンロード >> a'
await page.locator(target).click()
download = await download_info.value
await download.save_as(f'dl/{title}.png')コード
import asyncio
from playwright.async_api import async_playwright
import time
#----------------------------------------------------
# playwright run
#----------------------------------------------------
#### 3. Download data(Click download button) [async]
async def download_task(title,page):
async with page.expect_download() as download_info:
target=f'text={title} ダウンロード >> a'
await page.locator(target).click()
download = await download_info.value
await download.save_as(f'dl/{title}.png')
async def main(url):
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context()
# Start tracing before creating / navigating a page.
await context.tracing.start(screenshots=True, snapshots=True, sources=True)
#### 1.Open url page
page = await context.new_page()
await page.goto(url)
#### 2. Get title of download button.
# ダウンロードボタンのタイトル名をリストで取得
titles = await page.locator('div.label-box-label.block-box-label.box-label > span').all_inner_texts()
# print(titles)
#### 並行処理 :3. Download data(Click download button) [async]
tasks = []
for title in titles:
tasks.append(asyncio.create_task(download_task(title,page)))
await asyncio.gather(*tasks)
# Stop tracing and export it into a zip archive.
await context.tracing.stop(path = "trace_async_task.zip")
#### 4. Close page
await page.close()
await context.close()
await browser.close()
return "OK"
#----------------------------------------------------
# main
#----------------------------------------------------
if __name__ == "__main__":
print(f'--> Download Start[async_task].')
start = time.time()
# Download Test Page
url = "https://www.doestarian.com/python/playwright/download-test/"
# Playwright 実行
result = asyncio.run(main(url))
print(f'result:{result}')
end = time.time()
elapsed_time = end - start
print(f'経過時間:{elapsed_time:.2f} 秒')
trace解析
playwright show-trace .\trace_async_task.zip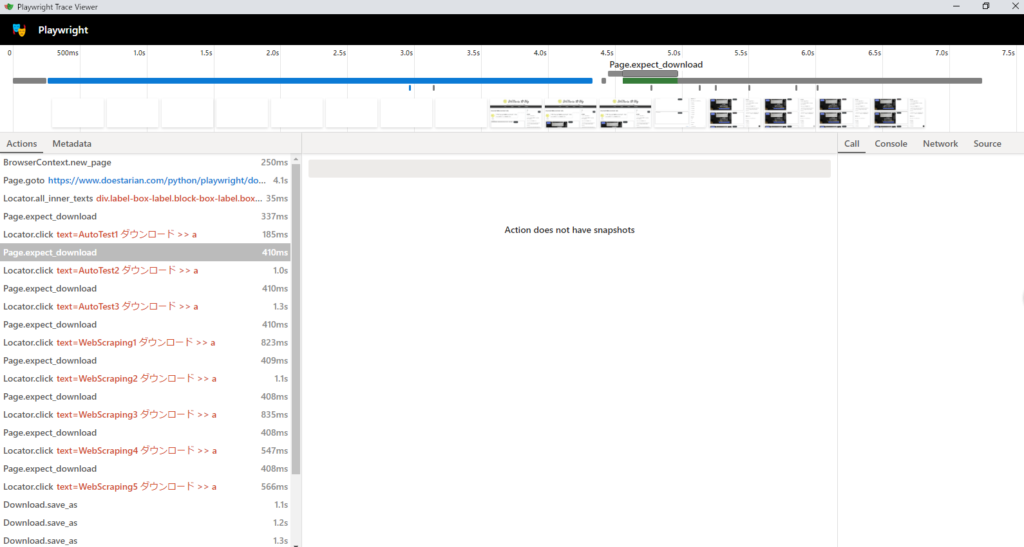
Download.save_asの時間は伸びましたが不要な待ち時間は無くなりました。
計測結果
main.pyの計測結果です。ちょっとですが、体感でも速くなった気がします。
経過時間:7.01 秒
経過時間:6.18 秒
経過時間:6.60 秒
経過時間:6.51 秒
経過時間:6.41 秒
2.4 比較結果
結果をまとめです。非同期+並行処理により変更前より29%も高速化できました。
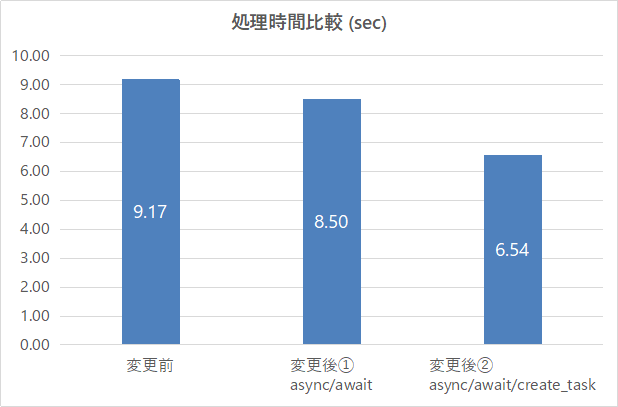
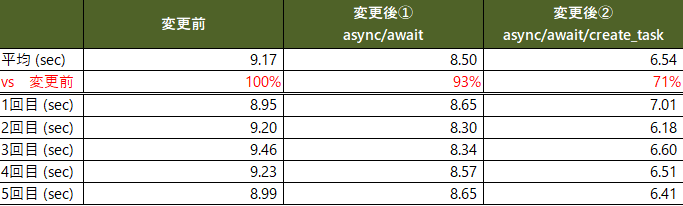
実験PCのスペック
CPU :Intel(R) Core(TM) i5-4200M CPU @ 2.50GHz
Memory:8.00 GB
OS : Windows 10 Pro (64ビット)
さいごに
今回は、ダウンロード”page.expect_download()”について学びました。
Playwrightは、まだまだ奥が深いですね。これからも学び続けようと思います。
(ドエスタ)
今回の教訓でPlaywright におけるdoestar 3か条ができたよ
- Codegen でサンプルコードを生成しよう
- Traceで時間解析しよう
- async/await +create_taskで処理時間を短縮しよう


コメント